
文章对数据ETL中的反作弊应用进行了简单的梳理分析,希望通过此文能够加深你对数据ETL的认识。

一、反作弊作用于哪个阶段?
在做反作弊之前,我们要明确整个数据从底层到数据中台过程中流向是什么样的。这里,我梳理了一个模型,它可以反映这一过程。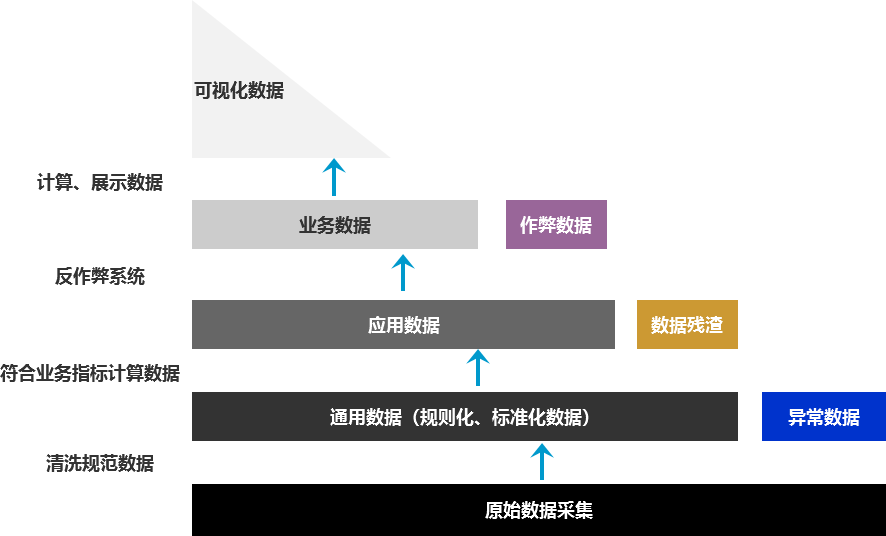
数据从原始采集经过“清洗规范”,会形成“通用数据”,这里会过滤掉异常数据供上层使用。
通用数据会根据业务场景,聚合成符合业务指标计算的数据,即“应用数据”,比如说是“主题场景”的数据。“主题场景”的数据可以是基于大背景的场景(横向),如:推荐业务场景、搜索业务场景。也可以是垂直到业务线的场景(纵向),如:某项购物时的推荐场景、短视频搜索的业务场景。这一过程会产生“数据残渣”,这部分数据是暂时没有应用场景的数据。
比如,在推荐商品时,你只取了用户的年龄、性别等作为特征,剩下的用户姓名这个特征数据在这个场景应用不到,它就成了暂时的“数据残渣”。不过,你可能在信贷业务场景中使用到这个特征数据(用户姓名),那种应用场景下它就不是“数据残渣”。
应用数据只是一个基础可用的数据集市,还需要经过反作弊系统来过滤掉具体应用场景下的作弊用户或者设备,形成“业务数据”。
最终,跟进业务需求等制定数据指标、维度等计算逻辑,并在数据中台形成可视化数据。
综上,我们可以发现,反作弊是在“应用数据”与“业务数据”之间work的。
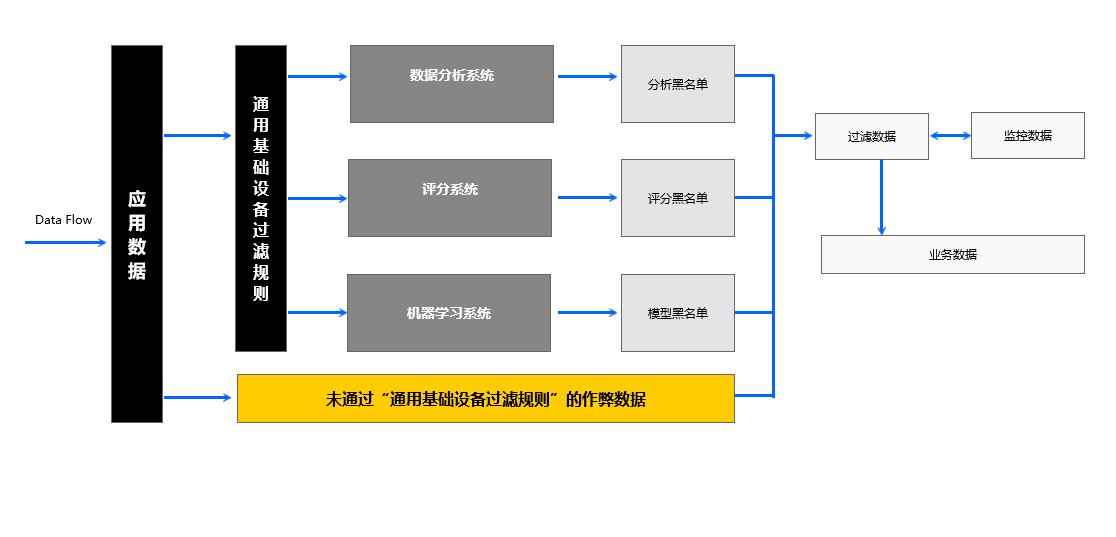
二、反作弊基础模型


 闽ICP备13000641号-4
闽ICP备13000641号-4