
编辑导读:随着“数智化”时代的到来,我们生活中的方方面面都离不开数据,而你真的了解数据吗?本文将为你重新解读数据的概念和价值,以及数据的价值是如何在“数智化”时代下一步一步得到运用与升华的;因内容颇多,笔者将分几期为大家进行讲解。

一、前言
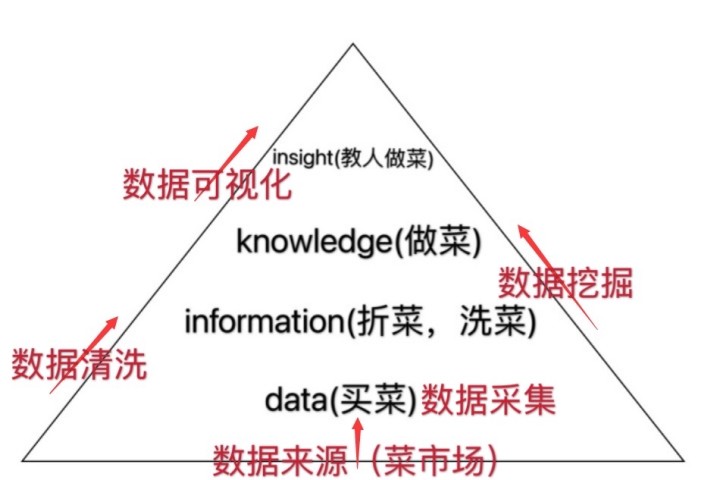
上一期文章中,我们已经了解到“数据”是一个庞大的体系(如下图所示);并用了“洗菜、择菜”的例子,为大家讲解数据清洗的含义;而今天笔者主要给大家讲解当净菜备好后,如何对净菜进行加工烹饪,让它变成有价值、有意义的美味佳肴,即数据挖掘的过程。
二、数据挖掘(烹饪)
数据挖掘是对既定的“净数据”进行加工利用的过程,我们可以把它看作是烹饪加工的过程。
而数据挖掘是有一定规则和相应模型的,这一点我们也可以通过一个类比进行理解。
清洗后的高质量数据就像是“净菜”,而数据挖掘模型就像是各种“菜系”,我们知道,就算“净菜”材料一致,但菜系(数据挖掘模型)不同,最终得到的成品也是截然不同的!
下面是数据挖掘中较为常见的几个“菜系”(模型),下面我们配合模型对应的使用场景逐一阐述
总的来说,数据挖掘模型可以通过“监督模式”进行大致分类,分类为监督模型、非监督模型:
- 监督模型:简单的说,就是让机器学会举一反三,它好比学生在学习时已知题目和答案,去学习分析如何解题一样,下次遇到一样的或者类似的题目就会做了;监督模型内的数据分为训练集和测试集,常见模型有决策树、LOGISTIC线性回归等。
- 非监督模型:简单的说,就是略去了监督模型中”举一反三“的过程,输入的仅仅是一堆数据,没有标签,也没有训练集和验证集之分,让算法根据数据本身的特征去学习,常见模型一般有clustering。

了解了数据挖掘的基本类别,下面我们来切入场景,看一看这些具体的算法模型如何帮助我们在现实场景中进行数据挖掘。
聚类分析——其中以K-Means算法最为典型。
原理与步骤:
- 选取K个中心点,代表K个类别;
- 计算N个样本点和K个中心点之间的欧氏距离;
- 将每个样本点划分到最近的(欧氏距离最小的)中心点类别中——迭代1;
- 计算每个类别中样本点的均值,得到K个均值,将K个均值作为新的中心点——迭代2;
- 重复234;
- 得到收敛后的K个中心点(中心点不再变化)——迭代4;
使用场景:商业领域,聚类分析常结合(RMF模型)被用来进行客户细分;生科领域,聚类分析常被对动植物分类和基因进行分类,进行种群研究。
实操案例:运用K-Means算法对航空业客户进行价值衡量和细分。


 闽ICP备13000641号-4
闽ICP备13000641号-4