
本文内容来自神策数据《智能推荐——应用场景与技术难点剖析》闭门会分享内容整理,分享者将我们介绍:如何从四个方面做一个推荐系统。

在工作中,大家遇到的与推荐系统相关的问题是:“数据太稀疏、数据没有形成闭环、数据没办法跟其他系统结合”等等。
这些内容是摆在我们面前的实际问题,那么当我们真正要开始做一个推荐系统时,需要从几方面考虑问题呢?
1. 算法:到底应该选择什么样的算法?无论是协同过滤还是其他算法,都要基于自己的业务产品。
2. 数据:当确定了算法时,应该选择什么样的数据?怎样加工数据?用什么样方法采集数据?
有句话叫做“机器学习=模型+数据”,即便拥有了一个很复杂的模型,在数据出现问题的情况下,也无法在推荐系统里面发挥很好的效果。
3. 在线服务:当模型训练完毕,数据准备充分之后,就会面对接收用户请求返回推荐结果的事项,这其中包含两个问题:
(1)返回响应要足够迅速,如果当一个用户请求后的一秒钟才返回推荐结果,用户很可能因丧失耐心而流失;
(2)如何让推荐系统具有高可扩展性。当 DAU 从最初的十万涨到一二百万时,推荐系统还能像最初那样很好地挡住大体量的请求吗?这都是在线服务方面需要考虑和面临的问题。
4. 评估效果:做好上述三点,并不代表万事大吉。
一方面,我们要持续迭代推荐算法模型与结构;另一方面要去构建一套比较完整、系统的评价体系和评估方法,去分析推荐效果的现状以及后续的发展。
我会从以上四个方面,跟大家分享一下我们在实际情况中遇到的一些问题以及总结出的解决方法。
一、算法
在各种算法中,大家最容易想到的就是一种基于标签的方法。
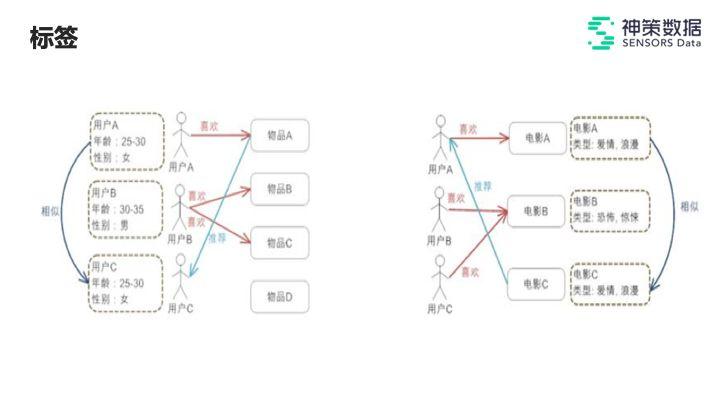
如上图所示,标签可分为两种:
1. 用户标签:
假设我们拥有一部分用户标签,知道每一个用户的年龄、性别等信息,当某类年龄和某种性别的用户喜欢过某一个物品时,我们就可以把该物品推荐给具有同样年龄、性别等用户标签的其他用户。
2. 内容标签:
与用户标签的思路相似,如果用户喜欢过带有内容标签的物品,我们就可以为他推荐具有同样标签的内容。
但很明显,这种基于标签的方法有一个重要的缺点——它需要足够丰富的标签。也许在多产品中,可能并没有标签或者标签数量非常稀疏,所以标签的方法显然不足以应对。
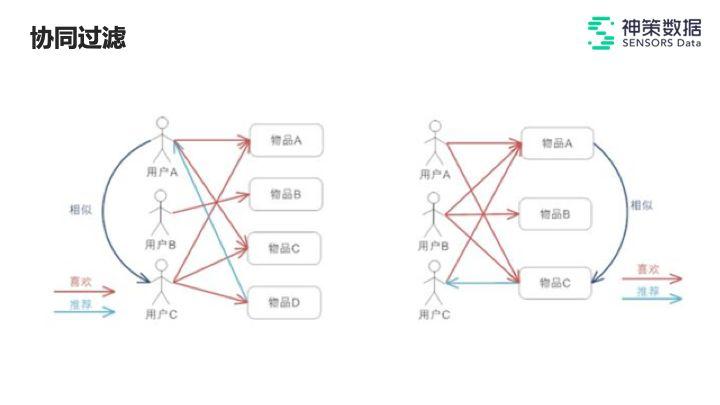
另外,协同过滤也是一种非常经典、被较多人提及的一种方法,是一种常见且有效的思路。
随着技术的不断发展,基本从 2012 年以后,深度学习几乎被整个机器学习界进行反复的讨论和研究。
谷歌在 2016 年提出一套基于深度学习的推荐模型,用深度学习去解决推荐的问题,利用用户的行为数据去构建推荐算法。


 闽ICP备13000641号-4
闽ICP备13000641号-4