
数据仓库是所有产品的数据中心,公司体系下的所有产品产生的所有数据最终都流向数据仓库,可以说数据仓库不产生数据,也不消费数据,只是数据的搬运工。

记得很久以前曾有一位前辈和我说过:“进来的数据是垃圾数据,出去也是垃圾数据”。
在实际环境中,往往我们一条业务线会由多个不同的系统支撑组成(例如:很多电商后端业务线都区分为库存系统、售后系统、采购系统、CRM系统等)。这些系统由于本身设计的缺陷或业务流程变更等问题,所产生的数据往往都是有缺失、冗余的,如果直接使用这些数据去进行数据分析,那**分析出来的结论多半也不正确。
因此需要有个数据产品来对数据进行整合加工,而数据仓库就是这样一款产品。
要想了解怎么搭建数据仓库,首先需要明白数据仓库的作用:
- 存储数据
- 校准数据
- 整合数据
- 输出数据
基于以上几点,需要将数据分层次管理,每一层分工合作,对数据进行不同程度的处理,如同工厂里的流水线一般,从而确保数据的生命性、生态性。
大数据体系整体架构
数据仓库并不是独立存在的一个个体,而是与整个大数据体系融为一体的——换句话说,数据仓库就像人的心脏,人只有心脏而没有其他器官是无法单独存活下来的。
大数据体系架构如图所示:
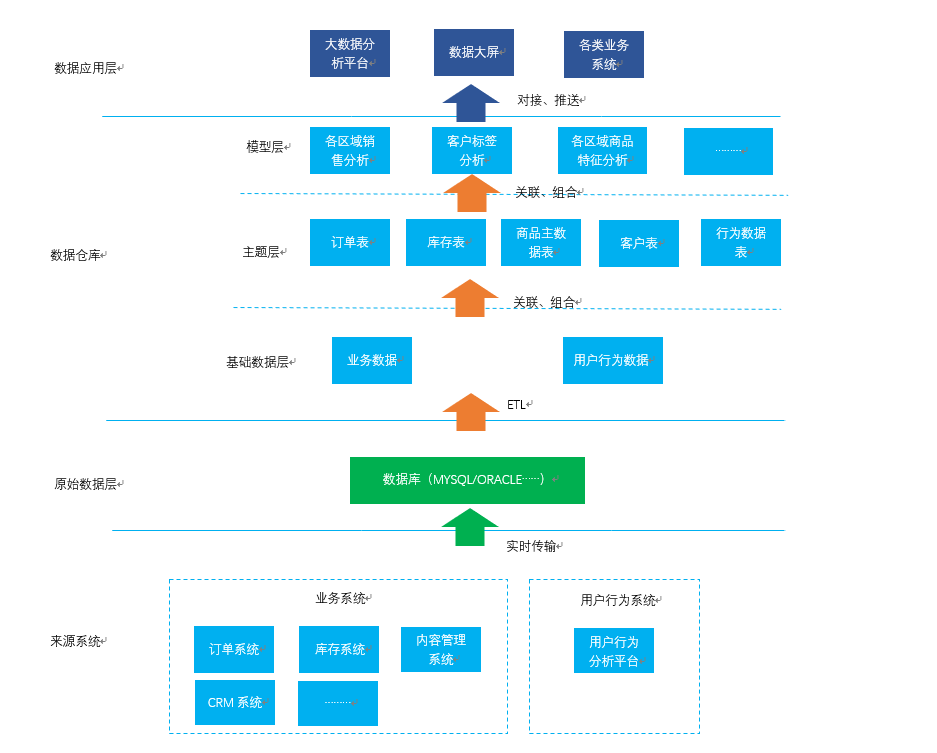
来源系统
数据的来源系统,可以理解为数据的收集系统。
如图所示为基于电商业务下的大数据体系,因此数据大体可分为业务数据和用户行为数据,其来源系统更多是与电商业务相关的后端订单、库存等业务系统以及前端商城带来的用户行为数据。
原始数据层
顾名思义,即存放从来源系统过来的原始数据,所谓原始数据——即未经过任何加工处理的数据。
这一层次咋看之下有点多余,但实际上是有所考量的:
1)将数据仓库与业务系统分隔开
数据仓库的数据,实时性要求不高,而准确性、清洁型必须较高,因此清洗的脚本繁多。如果每条数据都实时传送到数据仓库的话,那脚本执行的频率将非常高,所占用的系统资源也随之增加。
2)分担业务系统的报表任务
总所周知,搭建大数据体系架构所使用的硬件资源是相对较高的,而业务系统往往只是支撑业务持续开展,从性能上往往无法支撑大数据量报表的导出。因此,原始数据层可以承载此项功能,业务系统数据传输的实时性也保证了从原始数据层导出的数据符合业务人员对报表实时性的需要。
数据仓库
一般来说,数据仓库可区分为三层:基础数据层、主题层、模型层


 闽ICP备13000641号-4
闽ICP备13000641号-4